内部资料,请扫码登录
pigcloud
本章节将指导您快速入门 PIG AI 的 RAG (检索增强生成) 功能。为了简化部署流程,我们使用阿里百炼平台提供的模型服务,无需自行部署 Ollama 等模型。先熟悉本章节内容,再深入研究私有化部署章节方案,一口吃不了大胖子。
PIG AI 平台默认使用阿里云百炼平台提供的模型服务
| 模型类型 | 模型名称 |
|---|---|
| 聊天模型 | qwen-max |
| 向量模型 | qwen-text-embedding |
| 视觉模型 | qwen-vl |
# 一、配置向量数据库
PIG AI 在2025.3版本已全面接入Milvus向量数据库,我们强烈推荐使用Milvus作为您的首选向量存储方案,它提供了更好的性能和扩展性。
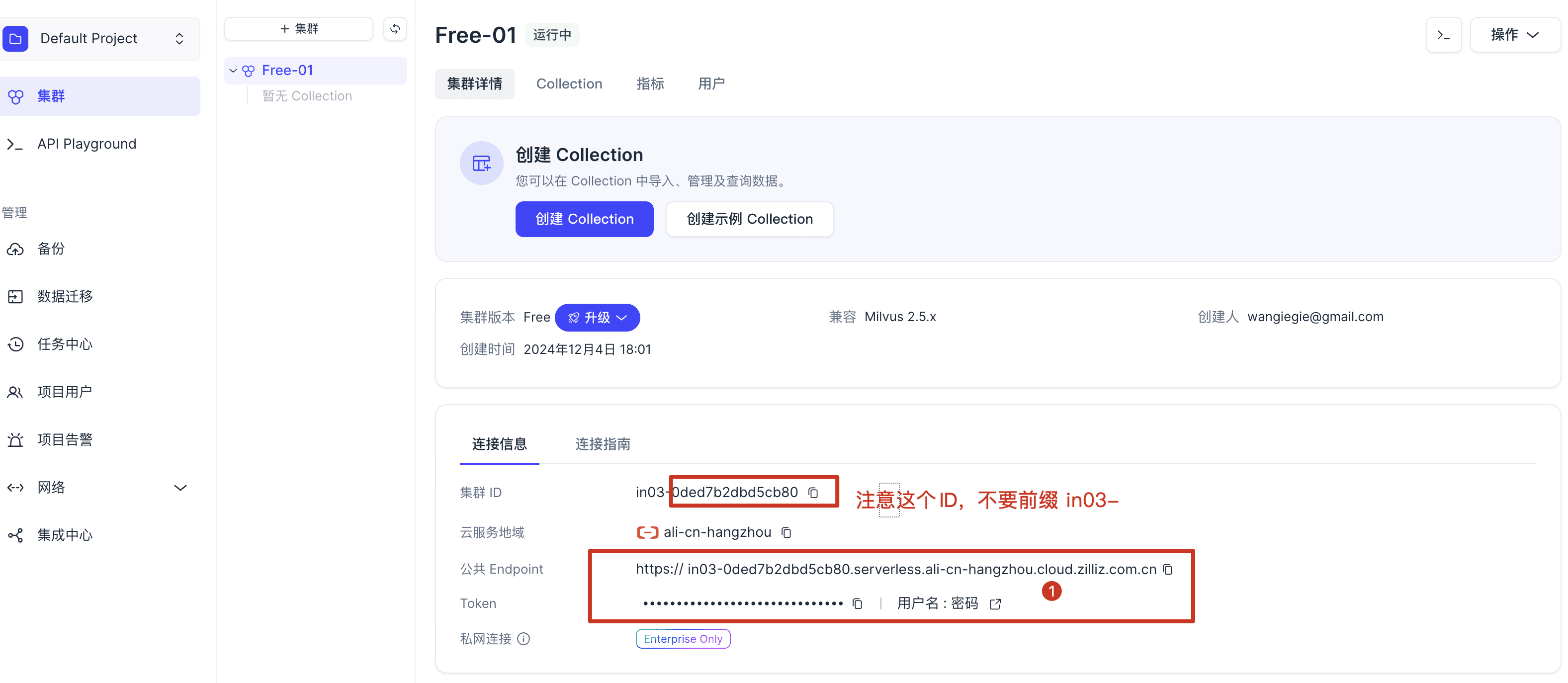
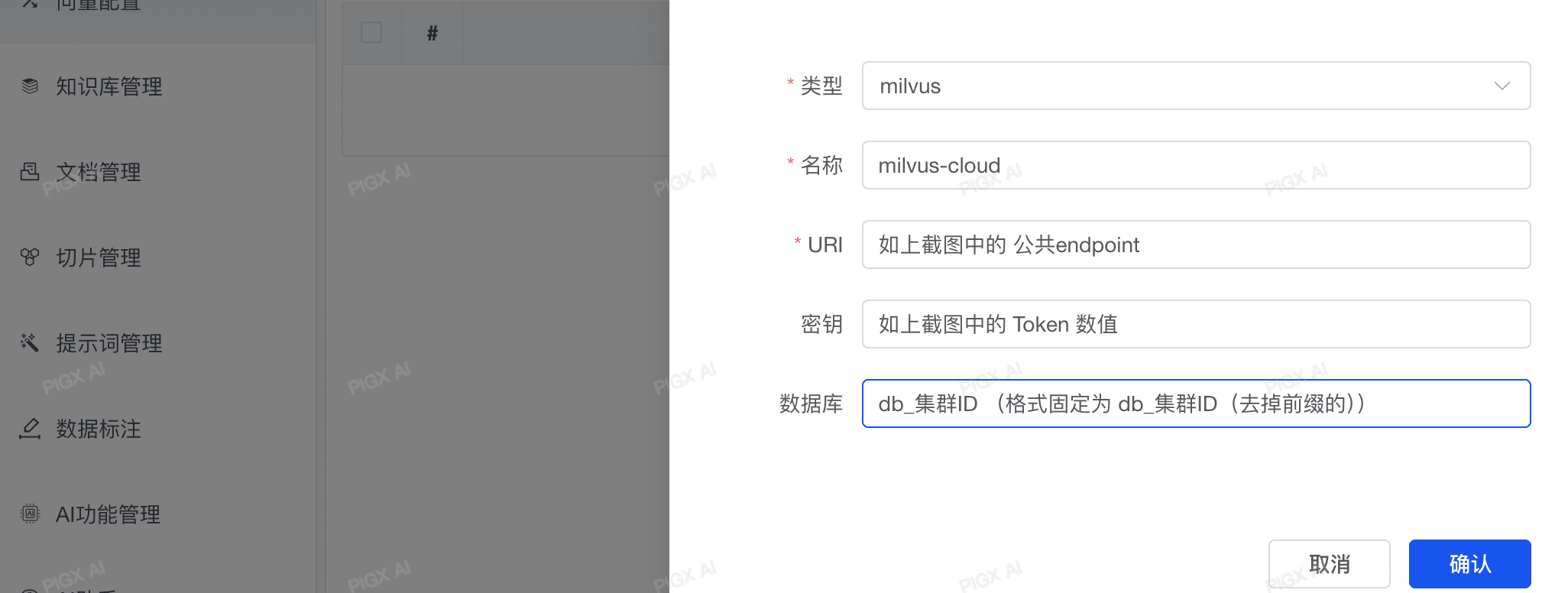
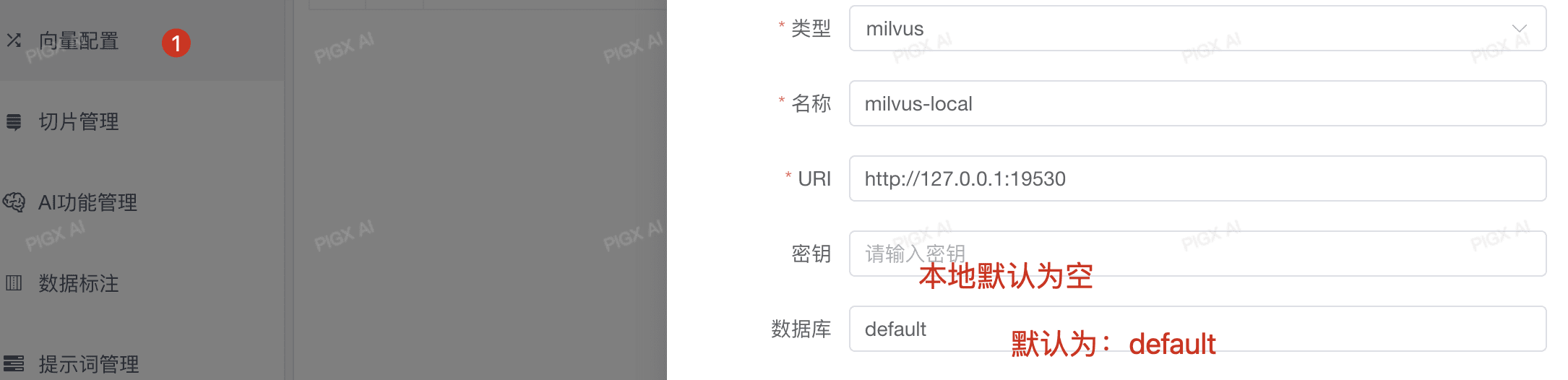
# 二、配置模型

# 2.0 大模型KEY
阿里云提供的免费用量,足够大部分用户使用,如果需要更多的用量,可以在阿里云购买(非常便宜,1块钱足够你玩很久)。

# 2.1 配置聊天模型

# 2.2 配置向量模型

# 2.3 配置视觉模型

# 3.1、创建知识库
- 知识库管理 > 新增

- 高级配置、安全配置参数 正常情况下不需要修改
- 匹配率、匹配条数: 决定了大模型匹配的幻觉率,比如匹配率越低,在知识内容较少的情况下,大模型匹配的幻觉率越高(胡说八道)。建议根据自己实际情况动态调整此处参数
# 3.2、上传资料
- 知识库管理 > 新增

文件上传后,请耐心等待后台处理文件等,过程状态参考如下说明
- 未切片: 上传文件后的状态
- 已切片: 文件已经解析并切割成一段段的文本
- 已总结: 通过大模型生成的整个文本的缩略信息,提高准确性
- 已训练(切片管理): 通过大模型生成的文本向量并入向量库

# 3.3、切片管理
上传至知识库的资料,会自动切片,切片管理可以查看切片详情,点击切片即可编辑。
当右上角显示已训练的标识时,则说明文档已经调用大模型生成了切片的向量并存储到向量数据库。

# 问答测试调用
AI 助手点击具体的文档库,进行针对性的问答调用。
